Growork
Empezó como una web para ayudar a candidatos hispanohablantes a trabajar en Suiza. Terminó siendo cuatro productos conectados: una web pública con pagos, un scraper de ofertas, una consola interna de operaciones y un portal privado para clientes.
4
productos conectados: web, scraper, Email OS y portal
54
API routes en la web pública
13
módulos NestJS en la web interna
10+
flujos de n8n en producción
La capa pública del producto: captación, planes, contenido SEO y conversión.
El proyecto
Una web que acabó necesitando una arquitectura de producto
Un candidato que quiere trabajar en Suiza no necesita solo información. Necesita que alguien prepare su CV, lo envíe a los hoteles correctos, gestione las respuestas y le muestre el progreso. Eso no se resuelve con una landing.
Captación y venta
Home, formulario de evaluación individual o en pareja, planes y precios dinámicos, checkout autenticado e invitado, blog SEO y tracking de conversión.
Operaciones conectadas
Twenty CRM para leads y clientes, scraper diario de ofertas, web interna para envíos y respuestas, n8n para documentos y Google Workspace para emails corporativos.
Experiencia privada
Portal con dashboard, candidaturas, respuestas, estadísticas, plan activo, documentos y chatbot IA con contexto acotado al caso del cliente.
El ecosistema
Cuatro productos que forman un único sistema operativo
Lo que el cliente ve como una plataforma es, por dentro, cuatro sistemas independientes que se sincronizan.
Web pública — growork.es
Next.js 16 · Stripe · Twenty CRM · n8n · PostgreSQL
Captación, evaluación, checkout, blog SEO y portal privado. El webhook de Stripe es el punto central de aprovisionamiento: crea el usuario, registra los servicios, sincroniza el CRM y envía los emails.
Scraper de ofertas de empleo
Python · FastAPI · Playwright · PostgreSQL · APScheduler
Cuatro scrapers (HotelCareer, Hogapage, Gastrojob, Hoteljob) que se ejecutan a diario, extraen emails con múltiples estrategias y alimentan la base de datos que usa el motor de envíos.
Ver caso de estudio →Web interna — Email Operations OS
NestJS 16 · Next.js · Gmail API · OpenAI · Google Workspace
La consola operativa real: motor de envíos diario con warmup progresivo, generación de emails con GPT-4o, clasificación de respuestas con IA y gestión automática de cuentas corporativas.
Ver caso de estudio →Portal privado del cliente
Next.js 16 · JWT · PostgreSQL · Twenty CRM · Web interna
El candidato ve candidaturas, respuestas, estadísticas, plan, documentos y un chatbot IA con contexto acotado. Combina tres fuentes distintas de verdad sin que el usuario lo perciba.
Ver caso de estudio →El flujo de datos
Evidencia visual
Las piezas que había que hacer encajar
Portal, pagos, web interna, automatizaciones, finanzas y arquitectura. Cada captura corresponde a un sistema real.
Cómo funciona
Los tres flujos que mejor explican la complejidad
No son features aisladas. Son procesos que cruzan frontend, backend, CRM, pagos, automatizaciones y decisiones de producto.
Evaluación pública
El primer contacto no termina en un email: arranca el sistema.
- 01Formulario individual o de pareja con datos, idiomas, disponibilidad, país y provincia.
- 02Subida de CV y carta en PDF con validación de archivo, MIME y magic bytes.
- 03Cloudflare Turnstile y rate limit por IP antes de tocar cualquier sistema externo.
- 04Creación o actualización del lead en Twenty CRM mediante GraphQL.
- 05Webhook a n8n para procesar los documentos y enviar el email de confirmación.
Pago y aprovisionamiento
Stripe confirma el dinero, pero el webhook convierte el pago en acceso real.
- 01Checkout autenticado y checkout invitado para comprar sin cuenta previa.
- 02Precios dinámicos desde Finance API con fallback local si la API no responde.
- 03Webhook idempotente: un UPDATE condicional evita duplicar usuarios o servicios aunque Stripe reenvíe el evento.
- 04Crea el usuario, registra client_services y sincroniza Twenty con backoff exponencial.
- 05El reloj del plan no empieza al pagar, sino cuando aparece el primer envío real.
Portal conectado
Una interfaz sencilla sobre tres fuentes de verdad distintas.
- 01PostgreSQL guarda usuarios, pagos, servicios, tokens, chat y rate limits.
- 02Twenty CRM aporta perfil, plan, pareja y estado comercial.
- 03La web interna aporta candidaturas, respuestas, documentos, adjuntos y métricas.
- 04El portal bloquea las vistas sin plan activo y funciona para individual y pareja.
- 05El chat IA recibe contexto acotado y se protege con sanitización y límites de uso.
Lo que fue difícil
La dificultad estaba en los estados reales, no en la tecnología
Elegir Next.js, Stripe o PostgreSQL no era lo complicado. Lo complicado era que cada integración tenía su propia forma de fallar, su propio ritmo y su propia definición de verdad.
No había una única fuente de verdad
Stripe conocía el pago; Twenty, el cliente; PostgreSQL, la sesión y los servicios; la web interna, las candidaturas; Finance, los precios. El trabajo fue conseguir que todas esas piezas se comportaran como un solo producto.
Los sistemas no llegan a la vez
El webhook de Stripe puede ejecutarse antes de que el workflow de Twenty haya creado el objeto Cliente. Por eso el sistema reintenta con backoff, deja estados recuperables y se autocorrige en las siguientes peticiones.
La pareja cambia el modelo mental
Un flujo individual se puede modelar de forma lineal. Una pareja exige vínculos, servicios compartidos, datos separados, precios distintos y sincronización cruzada entre Person y Cliente en el CRM.
La operación debía ser invisible
El usuario no necesita saber que existen CRM, workers, webhooks o identificadores internos. Necesita ver si su búsqueda avanza, qué se ha enviado y quién ha respondido.
Decisiones
Preguntas que obligaron a pensar como producto
Duda
¿Landing o plataforma?
Decisión
Convertir Growork en una plataforma completa.
Por qué importaba
La web pública solo resolvía la captación. En cuanto aparecieron pagos, seguimiento, CRM y candidaturas, hizo falta un sistema con estado propio.
Duda
¿Cuándo empieza el plan?
Decisión
En la primera candidatura enviada, no en el pago.
Por qué importaba
Alinea el producto con el valor entregado. Pagar no significa que el servicio haya empezado a operar.
Duda
¿El CRM como única base de datos?
Decisión
Twenty para la relación comercial; PostgreSQL para el estado operativo.
Por qué importaba
El portal necesita sesiones, pagos, tokens, rate limits y chat con control propio. No todo debe vivir en el CRM.
Automatizaciones
Los workflows que eliminan el trabajo manual
Cada flujo de n8n encapsula un proceso que antes requería intervención humana. Estas son dos de las piezas que mejor muestran cómo el sistema opera solo.
Motor de candidaturas
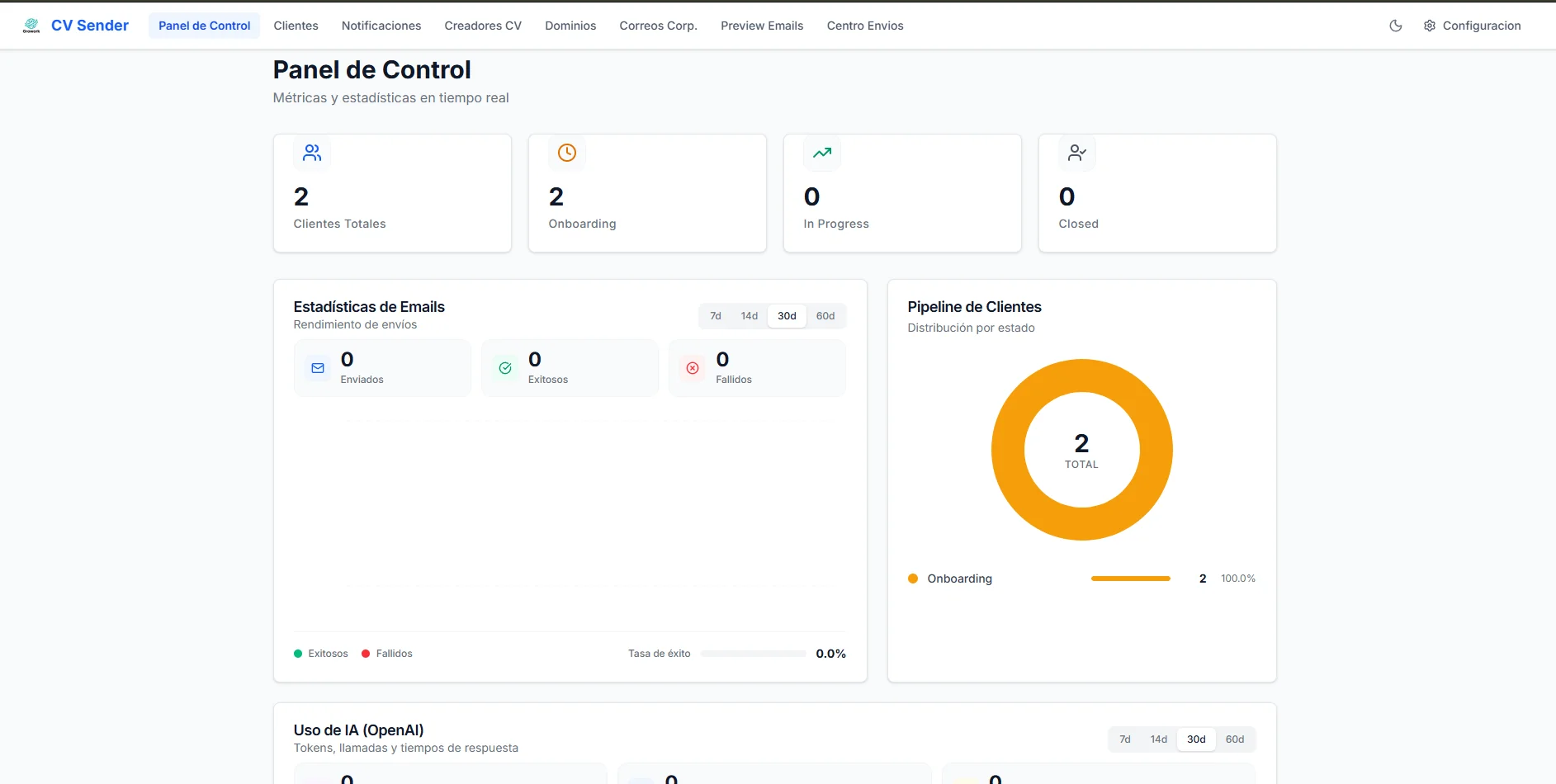
La web interna: el sistema que hace el trabajo real
La mayor parte del tiempo operativo de Growork no vive en la web pública, sino en una consola interna construida con NestJS y Next.js.
- →Scheduler diario (6:00 AM): crea los jobs de envío para cada cliente activo.
- →Worker cada minuto: genera el email con GPT-5 mini y lo envía por Gmail API.
- →Warmup progresivo: cada cuenta empieza con 2 emails/día y sube hasta 25.
- →Preview manual: aprueba o rechaza cada email antes de enviarlo.
- →Respuestas: lee Gmail, deduplica y clasifica con IA (entrevista, negativa, automática).
- →Google Workspace: crea cuentas corporativas cuando un cliente completa el workflow.
Ecosistema conectado
El acceso a las herramientas también tuvo que ordenarse
Growork acabó teniendo CRM, finanzas, web interna, n8n, base de datos, Dokploy y gestor de proyectos. Creé una web central para operar el ecosistema sin depender de favoritos ni servicios expuestos.
Ver Command Center